[DB] SQL 명령어 헷갈리는거 다 모아: ORDER BY, Aggregate Function, GROUP BY, HAVING, SELECT의 실행 순서
💋 인트로
안녕하세요 깃짱입니다.
소스 코드 ⇒ https://github.com/gitchan-Study/2023-sql-sample
GitHub - gitchan-Study/2023-sql-sample: 깃짱이 복잡한 SQL 명령어를 실습하기 위해 작성한 샘플 코드
깃짱이 복잡한 SQL 명령어를 실습하기 위해 작성한 샘플 코드. Contribute to gitchan-Study/2023-sql-sample development by creating an account on GitHub.
github.com
이번 포스팅은 쉬운코드님의 데이터베이스 강의를 바탕으로 작성했습니다.
💋 ORDER BY
✔️ 개념
조회 결과를 특정 attribute 기준으로 정렬해 가져오고 싶을 때 사용한다.
아무것도 설정하지 않으면 오름차순이고, 별도로 설정하려면 ASC, DESC를 명시해주면 된다.
✔️ 예시
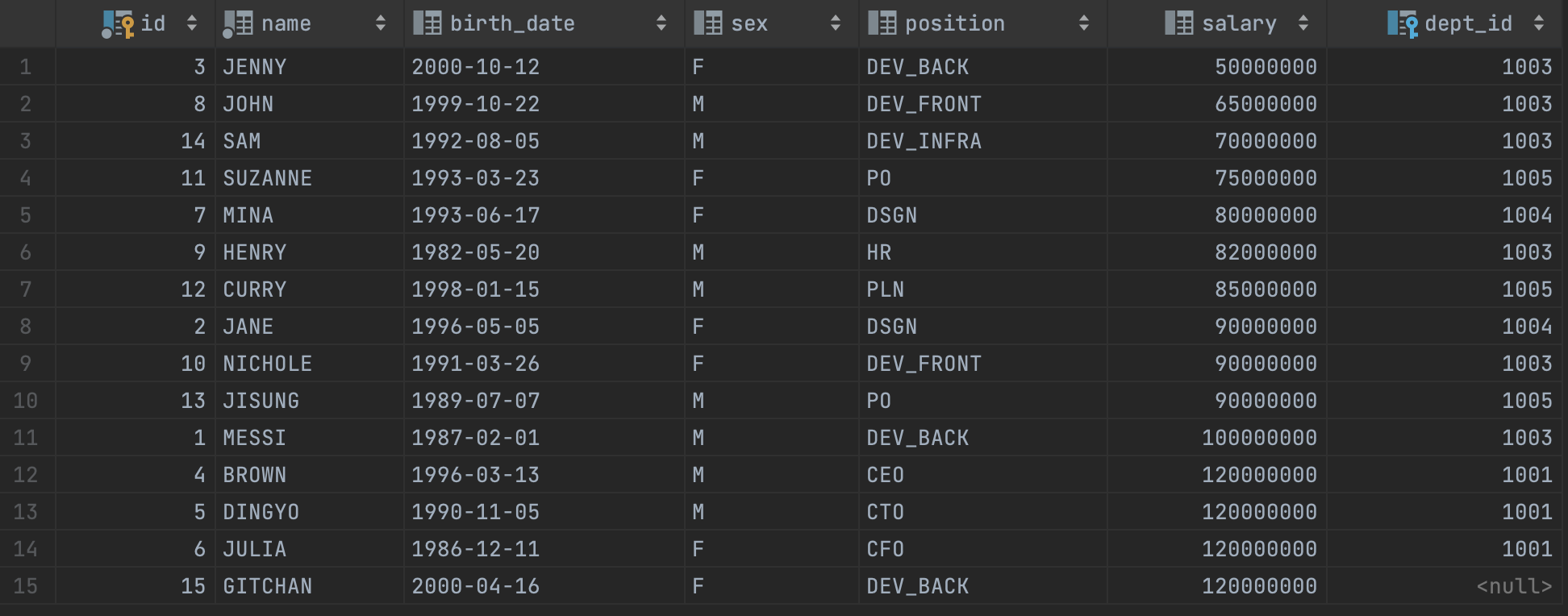
- 임직원을 연봉 기준으로 오름차순 정렬
select *
from employee
order by salary;
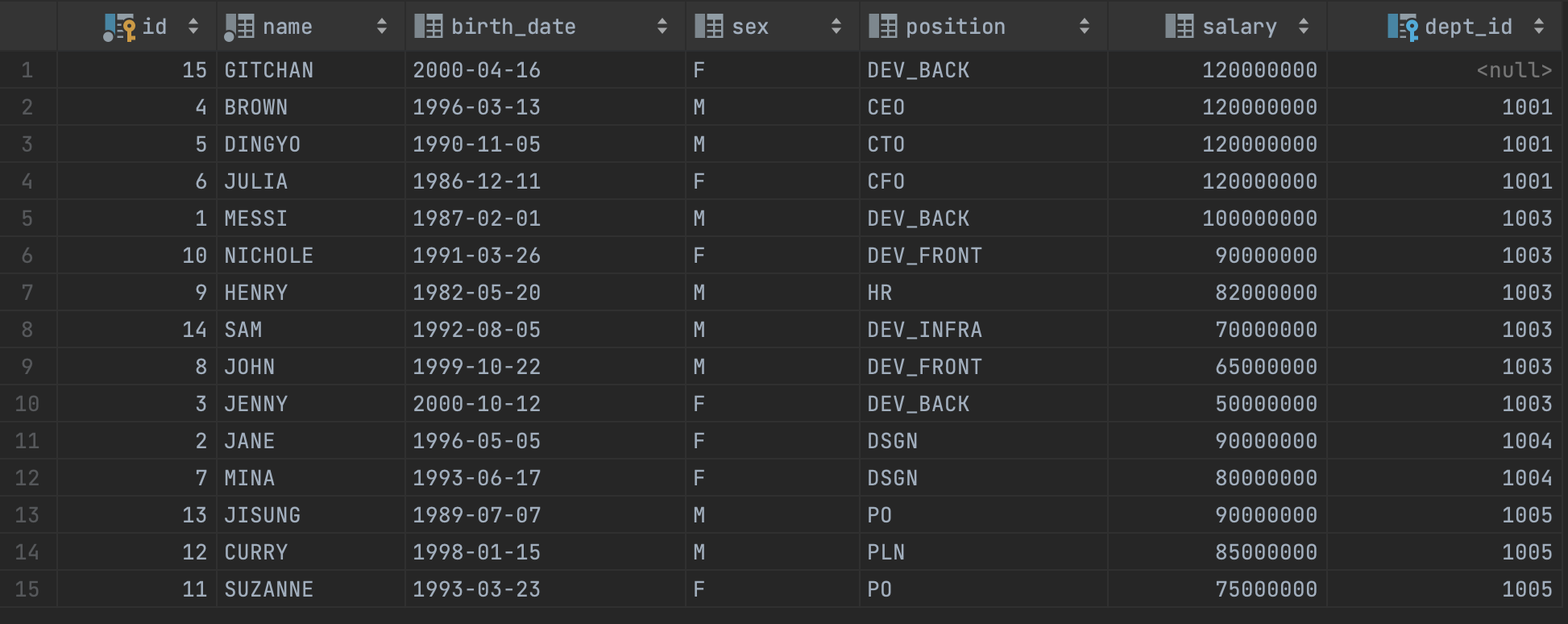
- 임직원을 부서 아이디 기준으로 정렬한 후, 연봉 기준으로 내림차순 정렬
select *
from employee
order by dept_id, salary desc;
💋 Aggregate Function
✔️ 개념
여러 tuple들의 정보를 요약해, 하나의 값으로 추출하는 함수
✔️ 종류
대표적인 예시로 COUNT, SUM, MAX, MIN, AVC 함수가 있다.
NULL 값들은 제외하고 요약 값을 추출한다는 점에 주의해야 한다.
✔️ 예시
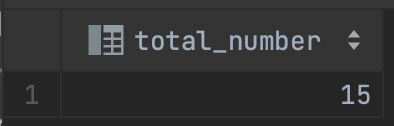
- 임직원 수 조회
select count(*) as total_number
from employee;
이 경우 * 대신에 하나의 attribute가 들어가는 경우에, null이 포함되면 null을 제외하고 count 하기 때문에 같은 결과를 보장할 수 없다는 점에 특별히 주의해야 한다!
- 프로젝트 2002에 참여한 임직원 수, 최대 연봉, 최소 연봉, 평균 연봉 조회
select count(e.id), max(e.salary), min(e.salary), avg(e.salary)
from employee e
join works_on wo on e.id = wo.empl_id
where wo.proj_id = 2002;

💋 GROUP BY
✔️ 개념
관심있는 attribute 기준으로 그룹을 나눠서, 그룹별 aggregate function을 적용하고 싶을 떄 사용한다.
기준이 되는 attribute는 grouping attribute라고 하고, 만약에 여기 null이 있는 경우에 null값을 가지는 튜플끼리 모아서 결과를 낸다.
✔️ 예시
- 각 프로젝트 별 참여한 임직원 수, 최대 연봉, 최소 연봉, 평균 연봉 조회
select wo.proj_id, count(e.id), max(e.salary), min(e.salary), avg(e.salary)
from employee e
join works_on wo on e.id = wo.empl_id
group by wo.proj_id;
group by에 사용된 attribute는 반드시 select 절에서 적어줘야만 한다. proj_id를 모르면 뭔 통계인지도 알 수 없기 때문에!

💋 HAVING
✔️ 개념
group by에 대한 결과로 나온 것에 대해 조건을 걸고 싶을 때 사용한다.
따라서 group by와 항상 함께 사용되며, aggregate function의 결과값을 바탕으로 그룹을 필터링하고 싶을 때 사용한다.
HAVING 절에 명시된 조건을 만족하는 그룹만 결과로 표시한다.
✔️ 예시
- 프로젝트에 참여한 인원이 7명 이상인 프로젝트에 대해서 각 프로젝트 별 참여한 임직원 수, 최대 연봉, 최소 연봉, 평균 연봉 조회
select wo.proj_id, count(e.id), max(e.salary), min(e.salary), avg(e.salary)
from employee e
join works_on wo on e.id = wo.empl_id
group by wo.proj_id
having count(e.id) >= 7;

💋 실전 예시
- 각 부서별 인원수를 인원수가 많은 순서대로 정렬해서 조회
select e.dept_id as dept_id, count(*) as empl_count
from employee e
group by e.dept_id
order by empl_count desc;
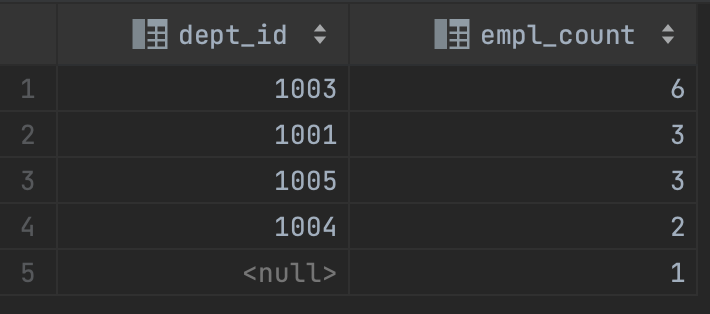
null이 있는 경우는 null을 가지는 튜플끼리 그룹핑해서 aggregate function을 적용한다.
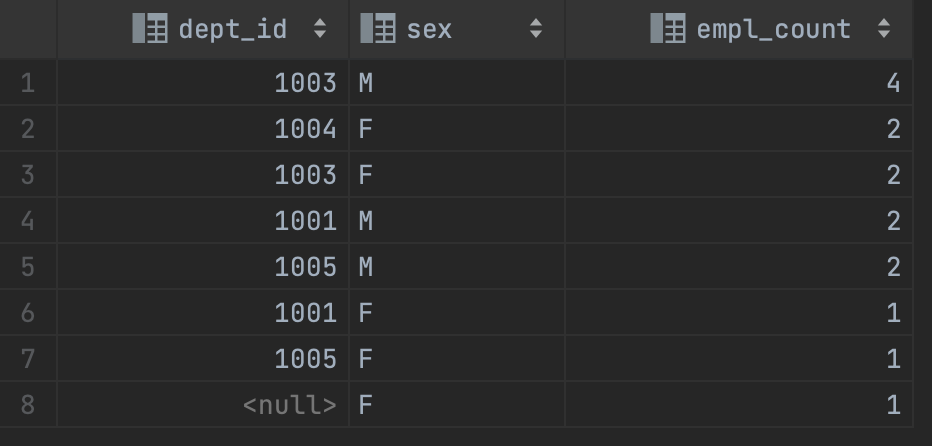
- 각 부서별 성별 인원수를 인원수가 많은 순서대로 정렬해 조회
select e.dept_id as dept_id, e.sex, count(*) as empl_count
from employee e
group by e.dept_id, e.sex
order by empl_count desc;
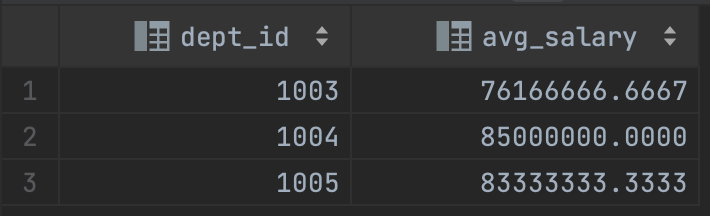
- 회사 전체의 평균 연봉보다 평균 연봉이 적은 부서들의 평균 연봉 조회
select e.dept_id, avg(e.salary) as avg_salary
from employee e
group by e.dept_id
having avg_salary < (select avg(e.salary)
from employee e);
회사 전체의 평균 연봉을 구하기 위해서 서브쿼리를 사용했고, 부서별로 그룹한 이후에 그룹을 기준으로 필터링하기 위해서 having을 사용했다.
- 각 프로젝트 별로 프로젝트에 참여한 90년대 생들의 수와 이들의 평균 연봉 조회
각 프로젝트별로 그룹핑 + 90년대 생 한정(각 튜플별 필터링이므로 WHERE)하면 될 것이다.
select wo.proj_id as proj_id, count(e.id) as count_90s, avg(e.salary) as avg_salary
from employee e
join works_on wo on e.id = wo.empl_id
where e.birth_date between '1990-01-01' and '1999-12-31'
group by wo.proj_id;
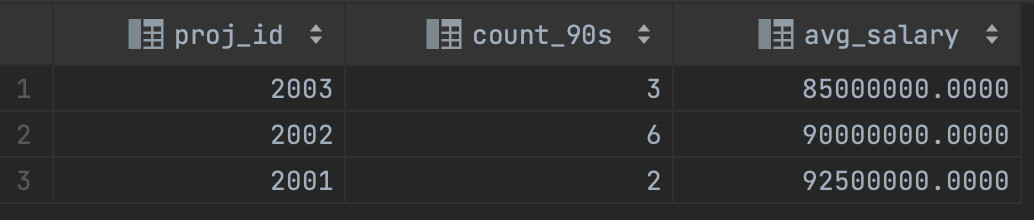
- 프로젝트 참여 인원이 7명 이상인 프로젝트에만 한정해 각 프로젝트 별로 프로젝트에 참여한 90년대 생들의 수와 이들의 평균 연봉 조회
곧바로 HAVING절에서 COUNT하게 되면, 그룹핑을 한 후에 그 그룹에 대해서만 COUNT하게 된다. 즉, 90년대 생들에 대해서만 COUNT를 하게 된다. 전체 인원을 기준으로 필터링해야 한다.
select wo.proj_id as proj_id, count(e.id) as count_90s, avg(e.salary) as avg_salary
from employee e
join works_on wo on e.id = wo.empl_id
where e.birth_date between '1990-01-01' and '1999-12-31'
and wo.proj_id in (select proj_id
from works_on
group by proj_id
having count(*) >= 7)
group by wo.proj_id;
따라서 이런식으로 where절에 서브쿼리를 넣어주어야 한다.

내가 걸어주려는 조건의 성격에 따라서, WHERE과 HAVING 중 어느 곳에 조건을 추가해야 할지 생각해야 한다.
💋 SELECT의 실행 순서
✔️ SELECT문의 형태
대략 이런 형태를 하게 된다.
SELECT attribute/aggregate_functions
from tables
WHERE conditions
GROUP BY group_attributes
HAVING group_conditions
ORDER BY attributes
그럼 개념적으로 이런 순서대로 실행하게 된다.
✔️ SELECT 실행 순서
개념적으로 이런 순서로 실행된다.
(6) SELECT attribute/aggregate_functions
(1) from tables
(2) WHERE conditions
(3) GROUP BY group_attributes
(4) HAVING group_conditions
(5) ORDER BY attributes
그치만 실제 실행 순서는 RDBMS의 구현(옵티마이저)에 따라다를 수 있다는 살짝 무책임한 말을 하며 마무리…

도움이 되었다면, 공감/댓글을 달아주면 깃짱에게 큰 힘이 됩니다!🌟
비밀댓글과 메일을 통해 오는 개인적인 질문은 받지 않고 있습니다. 꼭 공개댓글로 남겨주세요!