[자료구조] 스택(Stack), 큐(Queue): 개념, LinkedList vs ArrayDeque, 시간복잡도 비교
Computer Science 모아보기 👉🏻 https://github.com/seoul-developer/CS
GitHub - seoul-developer/CS: 주니어 개발자를 위한 전공 지식 모음.zip
주니어 개발자를 위한 전공 지식 모음.zip. Contribute to seoul-developer/CS development by creating an account on GitHub.
github.com
💋 스택(Stack)
✔️ 개념

- LIFO(Last In First Out) 형태로 데이터를 저장하는 선형 자료구조
- 가장 최근에 추가된 데이터가 가장 먼저 제거된다.
- 주요 동작
- 삽입(Push): 데이터를 스택의 맨 위에 추가하는 연산
- 제거(Pop): 스택의 맨 위에 있는 데이터를 제거하는 연산
- 피크(Peek): 스택의 맨 위에 있는 데이터를 조회하는 연산 (데이터를 제거하지 않음)
✔️ 사용 사례

✔️ 장단점
- 구현이 쉽다 ⇒
ArrayorLinkedList사용해서 쉽게 구현할 수 있음. - 메모리를 효율적으로 사용 ⇒ (일반적으로) 연속적인 공간에 데이터를 저장하기 때문에 효율적임!
LinkedList기반의 스택을 구현하면 노드들이 메모리 여기저기에 흩어져 있을 수 있음.


💋 스택(Stack)의 구현
✔️ 특징
스택의 데이터 중 가장 최근에 추가된 데이터만 접근할 수 있기 때문에, 스택의 첫 번째 데이터의 저장 위치를 알고 있어야 합니다.
이제 pseudocode를 통해서 각 구현에 대해 알아보자.
✔️ 종류
- 레지스터 스택
고정된 크기를 가지며 제한된 양의 데이터를 저장할 수 있습니다.- 일반적으로 CPU 내의
레지스터에 위치하므로빠른 속도로 액세스 가능합니다. - 메모리 스택
- 동적으로 크기가 조절될 수 있어 필요에 따라 더 많은 데이터를 저장할 수 있습니다.
- 일반적으로
RAM(메모리)에 위치하며, 상대적으로 접근 속도가 느릴 수 있지만대량의 데이터를 다룰 수 있습니다.
✔️ Top of the Stack
- 스택 연산에서 가장 먼저 접근 가능한 데이터
The top of the stack is always the element that is currently accessible for viewing or manipulation.
✔️ Push
- 스택의 맨 위에 데이터 추가
- 스택이 꽉 차면, Overflow condition
begin
if stack is full
return
endif
else
increment top
stack[top] assign value
end else
end procedure
✔️ Pop
- 스택에서 가장 최근에 추가된 데이터부터 삭제
- 스택이 비었으면, Underflow condition
begin
if stack is empty
return
endif
else
store value of stack[top]
decrement top
return value
end else
end procedure
✔️ 스택의 시간복잡도

- Push (추가)
- 스택에 데이터를 맨 위에 추가하는 연산입니다. 배열이나
LinkedList를 사용한 스택에서는 맨 끝에 데이터를 직접 추가합니다. 이 작업은 상수 시간에 수행되므로O(1)입니다. - 배열 기반 스택에서 크기를 늘리는 연산이 발생할 때에는 해당 연산이
O(n)의 시간 복잡도가 발생할 수 있지만, 자주 일어나는 일은 아니라서O(1)로 이야기합니다. - Pop (삭제)
- 스택의 맨 위에서 데이터를 제거하는 연산입니다. 배열이나 연결 리스트로 구현된 스택에서는 맨 위의 데이터를 직접 삭제합니다. 이 작업도 상수 시간에 수행되므로
O(1)입니다. - isEmpty (비어있는지 확인)
- 스택이 비어 있는지 확인하는 연산입니다. 스택이 비어 있는지 확인하는 연산은 스택의 상태와는 무관하게 스택의 시작 포인터를 살펴보면 되기 때문에, 상수 시간에 수행되므로
O(1)입니다. - Size (크기 확인)
- 스택의 데이터 개수를 확인하는 연산입니다. push(추가) 및 pop(삭제) 연산 시에 스택 크기를 업데이트하면서 관리하다가, 단순히 해당 변수의 값을 반환하면 되기 때문에 상수 시간에 수행되므로 O(1)입니다.
- 구체적인 방식은 구현 방식별로 조금씩 다를 수 있습니다.
✔️ 자바의 Stack
Stack은 Vector를 상속받은 클래스로, 부모 클래스인 Vector에서 정의된 클래스 변수들을 Stack 클래스에서 관리한다.
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
protected Object[] elementData; // 내부적으로 가지고 있는 배열
protected int elementCount; // 실제 데이터의 개수
protected int capacityIncrement; // 내부 배열의 메모리 사이즈를 관리
// ...
}
push()addElement()에서 내부 배열의 사이즈가 꽉 찼으면,grow()를 호출해 사이즈를 늘리고, 배열의 마지막에 데이터를 추가한다.
public E push(E item) {
addElement(item);
return item;
}
public synchronized void addElement(E obj) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = obj;
}
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
pop()peek()를 통해 가장 최근에 추가된 데이터를 받고, 마지막 그 데이터를 삭제한 뒤에 데이터를 반환한다.
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
peek()- 가장 최근에 추가된 데이터를 반환한다.
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
✔️ StackOverflowError

- 스택 메모리 공간을 다 썼을 때 발생하는 에러
- 보통 재귀 함수에서 탈출을 못해서 발생
- 탈출조건을 잘 써줘서 해결할 수 있다.
✔️ 참고자료
- https://www.geeksforgeeks.org/introduction-to-stack-data-structure-and-algorithm-tutorials/
- https://www.geeksforgeeks.org/implement-a-stack-using-singly-linked-list/?ref=lbp
- https://ko.wikipedia.org/wiki/스택
💋 큐(Queue)
✔️ 개념

- FIFO(First In First Out) 형태로 데이터를 저장하는 구조
- 가장 먼저 추가된 데이터가 가장 먼저 반환된다.
- 참고: 큐를 넓은 의미에서 그냥 기다리는 곳 정도로 사용할 때도 있는데, 이경우는 반드시 FIFO는 아닐 수도 있다. (예를 들자면, priority가 가장 높은 데이터가 먼저 반환되는 priority queue처럼?)
- 주요 동작
- 인큐(Enqueue): 큐의 맨 뒤에 데이터를 추가하는 연산
- 디큐(Dequeue): 큐의 맨 앞에서부터 데이터를 제거하는 연산
- 피크(Peek): 큐의 가장 앞쪽에 위치한 데이터를 조회하는 연산
✔️ 사용 사례
- 작업 대기열(Queue)
- OS 모니터의 bounded-buffer architecture에서 사용될 수 있습니다.
- 여러 작업이 도착하는 대기열을 효율적으로 관리합니다.
- BFS(너비 우선 탐색) 알고리즘
- 그래프 탐색 시에 사용되며, 각 레벨의 노드를 순차적으로 방문합니다.
- 프린터 대기열
- 여러 문서가 인쇄 대기 중일 때, 먼저 도착한 문서가 먼저 출력되도록 유지합니다.
- 캐시 메모리 관리
- CPU가 요청한 데이터를 일시적으로 저장하고 필요할 때 먼저 제공합니다.
✔️ OutOfMemoryError
- 자바에서 Heap 메모리를 다 썼을 때 발생
- 큐에 데이터가 계속 쌓이기만 해서 발생
- 큐 사이즈를 고정해서 해결할 수 있다.
- 큐가 다 찼을 때는, 예외 던지기, 매직넘버(null or false) 반환, 스레드 블락, 제한 시간 설정 등으로 해결할 수 있다.
- 자바의
LinkedBlockingQueue참고
💋 큐(Queue)의 구현
✔️ 자바의 ArrayDeque
자바에서 Queue ADT를 구현한 클래스로는 LinkedList나 ArrayDeque 등이 있습니다.
그중 ArrayDeque 에 대해서 알아보겠습니다.
- Java에서 제공하는
동적으로 크기가 조절되는양방향 큐(double-ended queue)를 구현한 클래스 - 선입선출(FIFO) 및 후입선출(LIFO) 두 가지 방식 모두 가능 ⇒ 큐, 덱 ADT를 모두 구현
- 큐의 확장된 형태로, 큐의 front과 rear 모두에서 삽입과 삭제가 가능

출처: https://docs.oracle.com/javase/9/docs/api/java/util/ArrayDeque.html
위에서 나온 특징들을 살펴보자
- no capacity restrictions
- 내부적으로 동적 배열을 사용하여 구현
- 크기 조절은 상수 시간이 아니지만, 여전히 효율적입니다.
- 큐의 삽입과 삭제가 상수 시간(O(1))에 이루어집니다.
public class ArrayDeque<E> extends AbstractCollection<E>
implements Deque<E>, Cloneable, Serializable
{
transient Object[] elements; // 내부적으로 배열 사용 (동적 배열로 구현)
transient int head;
transient int tail;
// ...
}
- 양방향 Queue
- 큐의 처음과 끝에서의 삽입과 삭제가 모두 가능 (중간에서 삭제가 일어나지 않음)
- 양쪽 끝에서의 연산이 상수 시간 ⇒ 맨 앞에서 데이터를 삭제하면
head만을, 맨 뒤에서 데이터를 삭제하면tail만을 변경하면 되기 때문입니다. - List 인터페이스 미구현
ArrayDeque는List인터페이스를 구현하지 않습니다.- 이로 인해 빠른 큐 및 덱 연산을 위한 구현이 가능하지만, 리스트의 일부 기능은 사용할 수 없습니다.
- Null 허용
- 스레드 안전하지 않음
ArrayDeque는 스레드 안전성을 보장하지 않습니다.- 동시에 여러 스레드에서
ArrayDeque를 수정하는 경우 외부에서 동기화를 해주어야 합니다. - 예를 들어,
Collections.synchronizedDeque메서드를 사용하여 동기화된ArrayDeque를 생성할 수 있습니다.
Deque<String> synchronizedDeque = Collections.synchronizedDeque(new ArrayDeque<>());
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e;
if (head == tail)
doubleCapacity();
}
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
elements[tail] = e;
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
}
주요 메서드들은 다음과 같습니다.
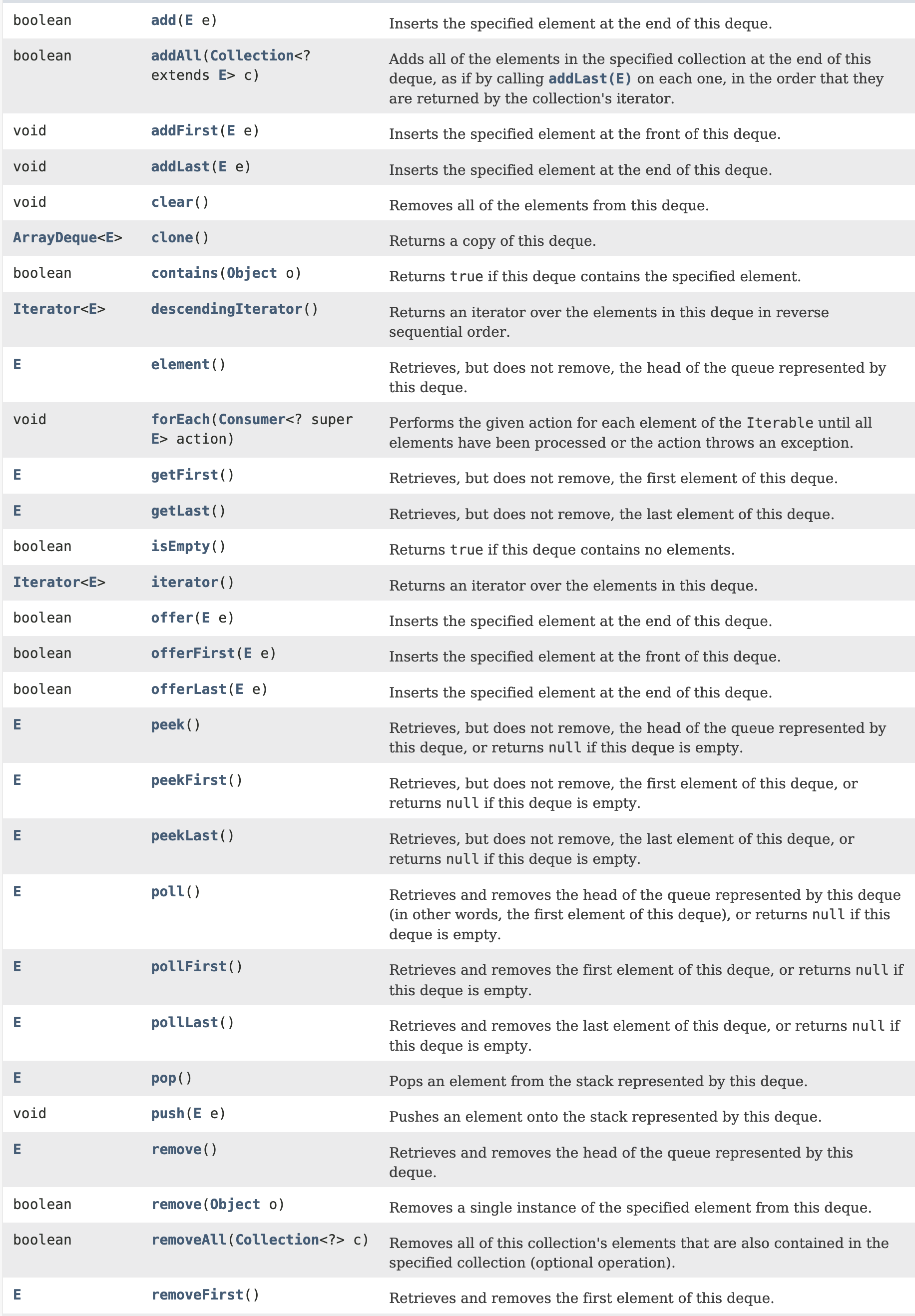
[개인적 궁금증] addFirst vs offerFirst
offerFirst는 addFirst를 내부적으로 호출하는 형태로 구현되어 있습니다.
public boolean offerFirst(E e) {
addFirst(e);
return true;
}
Java 문서에서도 offerFirst에 대해 "This method is equivalent to addFirst(E)"라고 설명하고 있습니다. 따라서 offerFirst를 호출하면 내부적으로는 addFirst가 호출되어 동일한 결과가 나타납니다.
✔️ LinkedList vs ArrayDeque
코드만 비교해보면, LinkedList는 List, Deque 인터페이스를 구현했고 ArrayDeque는 Deque 인터페이스를 구현했다. (List 인터페이스는 안구현했다는 점이 다르다!)
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
public class ArrayDeque<E> extends AbstractCollection<E>
implements Deque<E>, Cloneable, Serializable
지난 포스팅에서 ArrayList vs LinkedList를 다루면서, 일단 ArrayList를 쓰고 보자는 결론을 내렸었는데, LinkedList는 여기서도 비교당하고, 결국 진다.

암튼 중요한건 데이터 크기에 따라서 LinkedList, ArrayDeque로 실습을 진행했는데, 다음과 같은 결과를 얻었다.
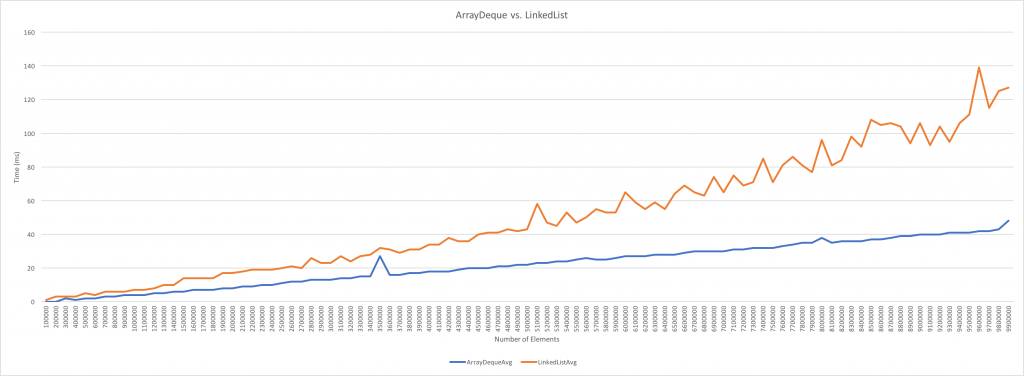
⇒ 데이터 만 개보다 적은 경우에는 크게 성능 차이 X (그냥 데이터 100개 200개 다루면 난리치지 말고 아무거나 쓰자)
⇒ 데이터 990만 개 이상으로 많을 때는 LinkedList가 같은 처리를 하는데 1.7배 가까운 시간이 걸림. (구려짐.)
근데 ArrayDeque는 List 인터페이스를 구현한 것은 아니라서 리스트의 일부 연산을 제공하지 않는다. ArrayDeque는 큐와 덱(양쪽 끝에서 추가 및 삭제가 가능한 큐)에 중점을 두고 있다. 따라서 리스트의 특정 기능을 사용하는 코드가 있다면 ArrayDeque를 대체하기 어렵다는 것에 주의하자!
이미 코드에서 LinkedList를 사용하고 있다면, 그 코드를 List 인터페이스에 기반한 형태로 작성했을 가능성이 크기 때문에 내 데이터 사이즈가 얼마나 되는지 가늠도 안해보고(= 성능 차이를 제대로 알아보지도 않고), ArrayDeque 로 바꾸게 되면 코드만 열라게 수정해야 될 수도 있다.
✔️ 참고자료
- https://stackoverflow.com/questions/6163166/why-is-arraydeque-better-than-linkedlist
- https://docs.oracle.com/javase/9/docs/api/java/util/ArrayDeque.html

도움이 되었다면, 공감/댓글을 달아주면 깃짱에게 큰 힘이 됩니다!🌟
비밀댓글과 메일을 통해 오는 개인적인 질문은 받지 않고 있습니다. 꼭 공개댓글로 남겨주세요!