[자료구조] B+Tree: 개념, 특징, B-Tree와의 차이점 정리
Computer Science 모아보기 👉🏻 https://github.com/seoul-developer/CS
GitHub - seoul-developer/CS: 주니어 개발자를 위한 전공 지식 모음.zip
주니어 개발자를 위한 전공 지식 모음.zip. Contribute to seoul-developer/CS development by creating an account on GitHub.
github.com
💋 B+Tree란?
✔️ 개념
- 데이터베이스 index에 자주 사용되는 자료구조
- B-Tree 계열의 Balanced Tree 종류 중 하나
MySQL의 InnoDB 스토리지 엔진은 주로 B+ Tree를 사용한다. B+ Tree B-Tree에서 파생된 개념이다.
B+Tree는 데이터베이스 인덱스와 파일 시스템 사용에 더 적합할 수 있도록 만들어졌다.
특징을 살펴보자!
✔️ 특징
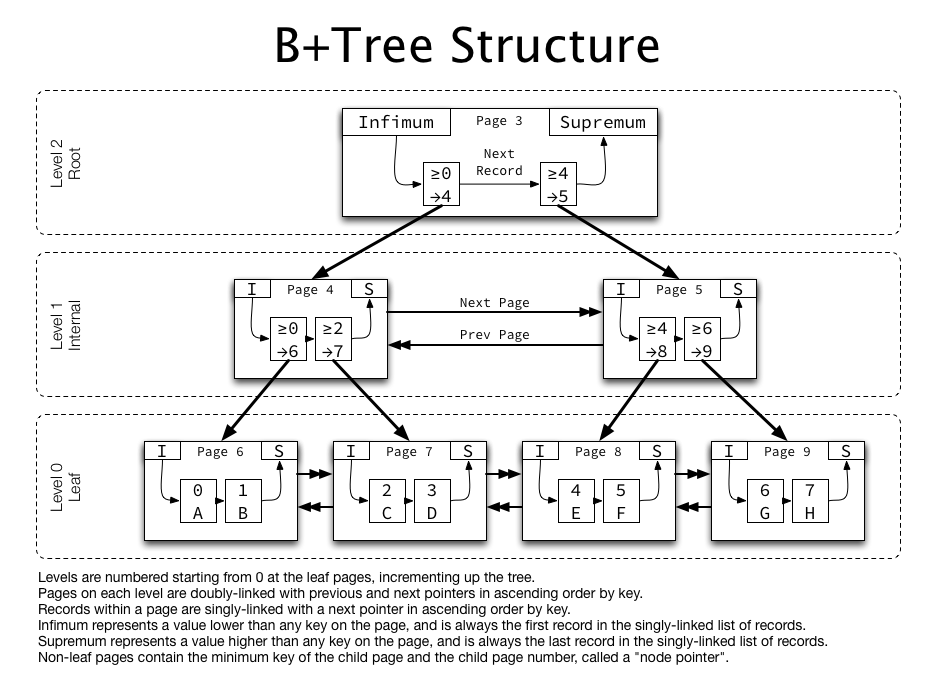
B-Tree와 차별화되는 특징은 아래와 같다.
- B+Tree의 리프 노드는 서로
연결 리스트로 서로 연결되어, 형제 노드끼리도 옮겨가며 조회할 수 있다. - 연결된 리프 노드의 리스트를 따라가면서 범위 쿼리를 할 수 있어서, 범위 검색 성능이 좋다.
- internal 노드에는 키만 저장되며, 이 키를 사용해서 자식 노드의 메모리 상 위치를 판단한다.
- internal 노드에는 데이터의 포인터도 없으며, 오로지 키만 저장된다.
- 데이터를 찾기 위한 포인터도 리프 노드에만 있다.
- internal 노드의 크기를 줄여 메모리 사용이 효율적이다.
- 실제 데이터는 리프 노드에만 저장되어 있다.
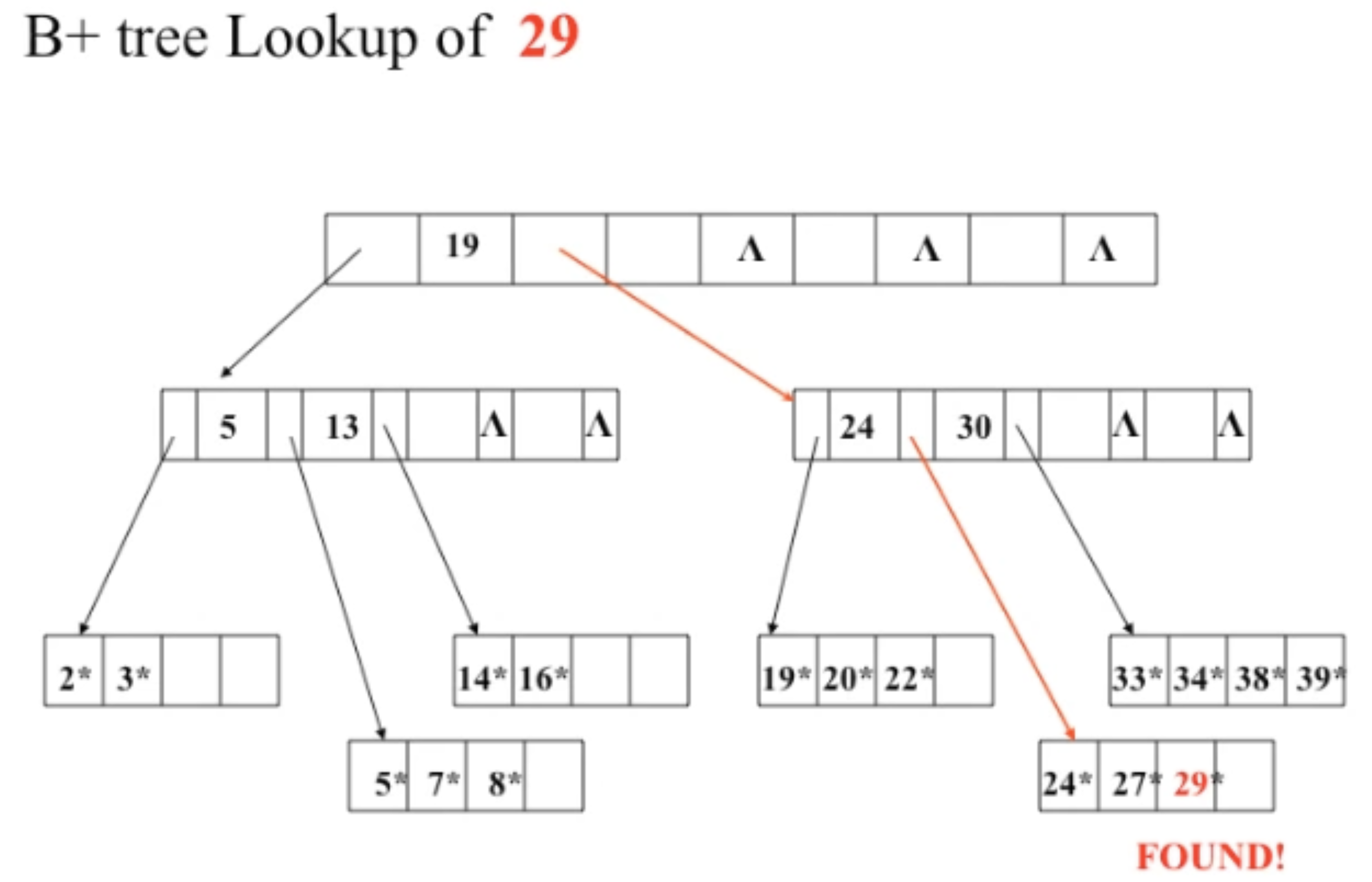
B-Tree에서 파생되었으므로, B-Tree와 유사한 특징은 아래와 같다.
- B+Tree 모든 노드의 키는 항상 정렬된 상태를 유지한다.
- internal 노드의 키와 리프 노드의 키는 모두 오름차순 정렬되어 있다.
- 새로운 데이터의 삽입 및 삭제가 비교적 간단하다.
- 삽입 시에는 리프 노드에 새로운 데이터를 추가한다.
- 삭제 시에는 데이터를 제거하면서 B+Tree의 균형을 유지한다.
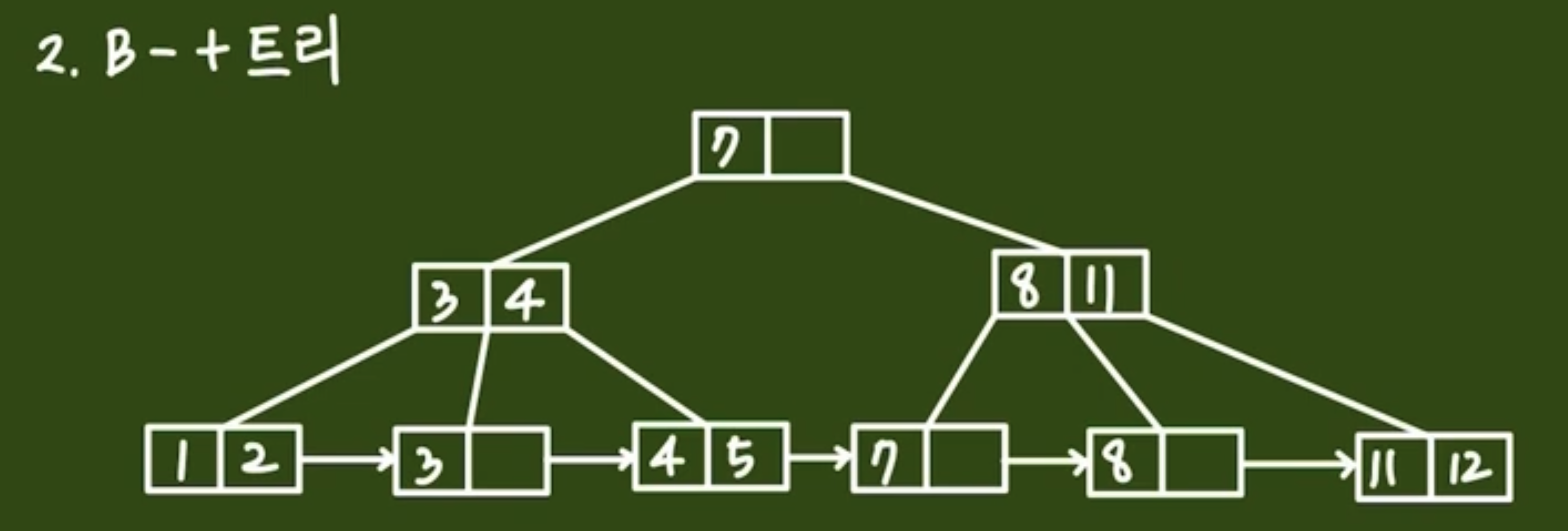
✔️ B-Tree vs B+Tree
B+ Tree B-Tree에서 파생된 개념이라고 하니깐, 두 가지를 비교해보면 좀 더 명확하게 알 수 있을 것이다.
- 검색 방법
- 데이터를 검색할 때 항상 리프 노드까지 이동하므로 검색 경로가 단순해진다.
- B-Tree: 모든 노드(internal node + leaf node)에
키와 값이 함께 저장 - B+Tree: internal 노드에는
키만 저장, 리프 노드에는키와 값이 저장됩니다. - 포인터의 사용
- 데이터를 찾기 위해 internal 노드를 항상 통과해야 조회한다. ⇒ 추가적인 단계 필요 (단점)
- internal 노드를 통하지 않고도 형제 노드로 이동 가능하고, 범위 검색이나 범위 쿼리가 쉽다.
- B-Tree: internal 노드의
포인터를 통해서만 리프 노드로 이동 가능 - B+Tree: 리프 노드끼리 서로
연결 리스트로 연결되어 있다. - 범위 쿼리와 범위 검색
- B-Tree: 범위 쿼리를 수행하려면 트리의 루트에서부터 리프 노드까지 이동하면서, 루트 노드, internal 노드에 있는 데이터까지 함께 조회해야 한다.
- B+Tree: 데이터는 리프 노드에만 존재하므로, 범위 쿼리는 리프 노드를 시작으로 연결된 리스트를 따라가면 모든 데이터를 조회할 수 있다.
- 순차 탐색 및 정렬
- B-Tree: 순차적인 탐색이나 정렬을 위한 추가적인 알고리즘이 필요해서 (예. inorder traversal) B+Tree보다 더 복잡하다.
- B+Tree: 연결된 리스트를 따라가면서 순차 탐색이 용이하며, 키들은 항상 정렬된 상태를 유지하면서 저장된다.
- 메모리 사용
- B-Tree: 리프 노드와 내부 노드가 각각 데이터와 포인터까지 가지고 있기 때문에 B+Tree보다 더 많은 메모리 공간을 차지한다.
- B+Tree: 데이터는 리프 노드에만 저장되고, internal 노드는 키만 갖고 있으면 되므로, 메모리 효율이 좋다.
다섯 가지 면에서 B+Tree가 성능이 개선된 모습을 보인다.
✔️ 데이터베이스 인덱스로 더 좋은 이유
B+Tree가 DB 인덱스에 사용되었을 때 더 좋은 점에 대해서 이야기하면 아래와 같다.
리프 노드를 제외하고 데이터를 담아두지 않기 때문에 internal 노드의 경우, 한정된 메모리 안에 더 많은 key들을 수용할 수 있다.
즉, 하나의 노드에 더 많은 key들을 저장하기 때문에 동일한 데이터 개수라면, 트리의 높이는 더 낮아진다.
cache hit를 높일 수 있을 뿐만 아니라, 범위 검색이나 범위 쿼리에도 큰 강점을 갖고 있으며, 상대적으로 굉장히 느린 secondary storage에 대한 접근 횟수가 현저히 줄어든다.
테이블 풀 스캔 시, B-Tree의 경우에는 데이터가 internal 노드와 리프 노드에 퍼져있기 때문에 모든 노드를 탐색해야 한다.
B+tree는 리프 노드에만 데이터가 존재하고, 존재하는 모든 데이터는 리프 노드에 있기 때문에 한 번의 선형탐색만 하면 되므로 매우 빠르다.
💋 참고자료
- https://www.geeksforgeeks.org/introduction-of-b-tree/
- https://algopoolja.tistory.com/122
- https://www.youtube.com/watch?v=CYKRMz8yzVU
- https://www.youtube.com/watch?v=aZjYr87r1b8 ⇒ 진짜 명강의임!
- https://zorba91.tistory.com/293
- https://zorba91.tistory.com/293

도움이 되었다면, 공감/댓글을 달아주면 깃짱에게 큰 힘이 됩니다!🌟
비밀댓글과 메일을 통해 오는 개인적인 질문은 받지 않고 있습니다. 꼭 공개댓글로 남겨주세요!