[AI/DL] 딥러닝의 발전(2): RNN에서 Transformer까지 — 순차 데이터와 Self-Attention 이해하기
자연어 처리(NLP)나 시계열 데이터는 입력의 순서가 중요합니다.
RNN, LSTM, Transformer는 이런 순차 데이터를 다루기 위해 만들어진 대표적인 구조들입니다.
🌍 RNN (Recurrent Neural Network)
이전 정보를 기억하면서 순서가 있는 데이터를 처리하는 신경망
- 순차 데이터 처리를 위해 등장함


| 기호 | 의미 |
|---|---|
| x(t) | 지금 단어의 벡터 |
| h(t-1) | 이전까지의 기억 |
| w(x), w(t) | 학습 가능한 가중치 |
| h(t) | 새로운 기억(은닉 상태) |
| tanh | 활성화 함수 → 기억 압축 |
이전 시점까지의 기억과 현재의 입력을 합쳐서 지금까지의 문맥의 요약을 만든 것을 은닉 상태(hidden state)라고 합니다. 즉, 새로운 기억을 만들 때 이때까지의 문맥을 반영하기 때문에 일반적인 NN과 달리 인접한 직전 정보까지의 내용을 반영할 수 있습니다.
RNN에는 치명적인 단점이 있는데, 본질적으로 순차적인 구조라는 것입니다.
시간 순서대로 데이터를 처리하기 때문에 이전 시점의 계산 결과가 나와야만 다음 시점의 계산을 시작할 수 있습니다.
예를 들어 문장 "I love deep learning"을 처리한다고 하면
t=1: "I" → h₁ 계산
t=2: "love" → h₂ = f(h₁, x₂)
t=3: "deep" → h₃ = f(h₂, x₃)
t=4: "learning" → h₄ = f(h₃, x₄)
여기서 h₃를 계산하려면 반드시 h₂가 먼저 나와야 합니다.
즉, 이전 단계가 끝나야 다음 단계로 넘어갈 수 있어서 GPU 병렬화 불가능합니다.
🌍 LSTM (Long Short-Term Memory)
RNN이 오래 기억을 못 하는 문제를 해결한 개선형 RNN
RNN은 이전 정보를 계속 곱해가면서 전달하기 때문에 시간이 길어지면 기울기(gradient)가 사라져서 오래된 정보가 증발합니다. (= 기울기 소실 문제, Vanishing Gradient Problem)
그래서 문장이 조금만 길어져도 앞부분 내용을 잊어버리는 문제가 발생합니다.
이를 해결하기 위해서 LSTM은 기억을 직접 관리하기 위해서 3개의 Gate를 도입합니다.
중요한 건 오래 두고, 쓸데없는 것은 잊어버리는 전략입니다
| 게이트 | 역할 |
|---|---|
| Forget Gate | 어떤 정보는 잊을지 결정 |
| Input Gate | 어떤 새 정보를 기억할지 결정 |
| Output Gate | 어떤 정보를 출력할지 결정 |
이 3개의 게이트가 하나의 “기억 셀(cell state)”을 조절하면서 장기 기억을 유지시켜줍니다.
LSTM은 구조적으로 RNN의 확장판이기 때문에, 순차적 특성(sequential dependency) 은 여전히 그대로 존재합니다.
즉, LSTM은 RNN의 단점을 기억 유지 측면에서 보완했을 뿐, 병렬 처리 불가능 문제는 여전히 남아 있습니다.
✅ RNN vs LSTM
| 구분 | RNN | LSTM |
|---|---|---|
| 기억 구조 | 단일 hidden state | hidden + cell state |
| 장기 기억 | 거의 불가능 | 가능 |
| 기울기 소실 | 심함 | 훨씬 완화됨 |
| 적용 분야 | 짧은 시퀀스 | 긴 문장, 번역, 음성 등 |
🌍 Transformer (2017)
“문장 안의 모든 단어가 서로를 직접 참고할 수 있게 만든 모델”
— 2017년 Google 논문 《Attention is All You Need》 발표
Transformer는 RNN을 완전히 대체한 모델로, RNN처럼 단어를 한 단어씩 순서대로 읽지 않고
문장 전체를 병렬로 한 번에 처리하면서 단어 간 관계를 Attention으로 계산합니다
✅ Self-Attention
각 단어가 문장 안의 다른 단어와 얼마나 관련이 있는지 점수를 계산
예를 들어,
The cat sat on the mat.
이런 문장이 있다면 “cat”은 “sat”과 강하게 연결되고, “the”와는 약하게 연결됩니다.
이 연결 강도(weight) 를 계산하는 게 바로 Attention입니당
계산하는 방식은 다음과 같습니다!
- 각 단어를 벡터로 바꿈 (embedding)
- 각 단어마다 세 가지 벡터를 계산
- Q (Query) : 내가 어떤 정보를 찾고 싶은지
- K (Key) : 내가 어떤 정보를 가지고 있는지
- V (Value) : 실제 정보
3. 모든 단어 쌍에 대해 연관성 점수 계산
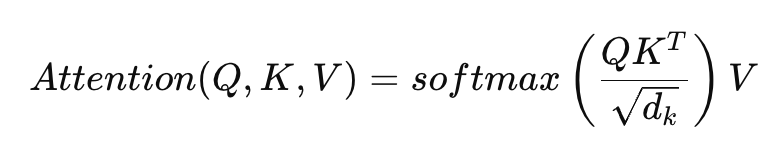
4. 이 점수를 가중치로 해서 문장 전체 정보를 종합
복잡하니 한번 예시를 통해 직접 해보겠습니당
✅ Self-Attention 계산 예시
Gitchan is hungry all the time
- 입력: 단어 임베딩
Transformer는 텍스트를 숫자 벡터로 변환해서 처리합니다. (=임베딩)
신경망은 숫자 이외에 String은 처리할 수 없기 때문에 신경망을 통과시키기 위해서는 임베딩을 통해 각각의 텍스트(토큰)를 숫자 벡터로 변환하는 과정이 필수적입니다.
"Gitchan" → [0.1, 0.4, 0.6, ...]
"is" → [0.3, 0.2, 0.1, ...]
"hungry" → [0.7, 0.9, 0.4, ...]
"all" → [0.2, 0.1, 0.5, ...]
"the" → [0.05, 0.3, 0.2, ...]
"time" → [0.6, 0.8, 0.9, ...]
2. Q, K, V 계산
각 단어 벡터(embedding)에 세 개의 가중치 행렬을 곱해서 Query(Q), Key(K), Value(V) 를 만듭니다.
Q = X * W_Q
K = X * W_K
V = X * W_V- Q(Query) : 이 단어가 “무엇을 찾고 싶은가?”
- K(Key) : 이 단어가 “어떤 정보를 가지고 있는가?”
- V(Value) : 이 단어의 “실제 내용 정보”
계산했을 때 이렇게 나왔다고 해 봅시당
"Gitchan" → Q=[0.9,0.3], K=[0.8,0.2], V=[0.7,0.4]
"is" → Q=[0.2,0.6], K=[0.1,0.8], V=[0.3,0.5]
"hungry" → Q=[0.5,0.9], K=[0.4,0.9], V=[0.6,0.7]
...
3. 유사도 계산 (QKᵀ)
각 단어의 Q와 다른 단어들의 K를 내적(dot product) 해서 두 단어가 서로 얼마나 관련 있는지 점수를 계산합니다.
예를 들어 “Gitchan”의 Q와 나머지 단어들의 K 비교
| 비교 대상 | Q·Kᵀ (유사도) | 의미 |
|---|---|---|
| is | 0.9×0.1 + 0.3×0.8 = 0.33 | 약간 관련 |
| hungry | 0.9×0.4 + 0.3×0.9 = 0.63 | 관련 큼 |
| time | 0.9×0.6 + 0.3×0.9 = 0.81 | 매우 관련 |
즉, “Gitchan”은 “hungry”나 “time”과 의미적으로 더 강한 연결을 가집니다.
4. Softmax로 확률화
Softmax 함수를 활용하면 값을 확률로 변환할 수 있습니다. 위에서 계산한 점수들을 softmax에 넣어서
가중치(Attention weight)로 바꿉니다.
[0.33, 0.63, 0.81] → Softmax → [0.20, 0.35, 0.45]즉, “Gitchan”은
- “is” 정보 20%
- “hungry” 정보 35%
- “time” 정보 45%
정도로 참고한다는 의미입니다. (softmax 함수 값의 합은 항상 1입니다)
5. V 정보 가중평균
이제 각 단어의 V 값(정보 벡터) 를 위 가중치로 가중 평균을 내면
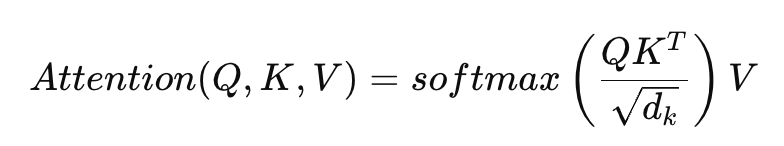
“Gitchan”이라는 단어의 최종 표현은 문장 전체 중 “hungry”와 “time”에 더 초점을 맞춰 만들어집니다.
✅ GPU 병렬 연산 가능
앞서 언급했던 RNN은 본질적으로 순차적인 구조이기 때문에 병렬 처리가 불가능합니다.
반면 Transformer는 Self-Attention을 사용하면서 완전히 구조가 바뀝니다.
- 모든 단어의 Q, K, V를 한 번에 계산합니다.
QKᵀ로 유사도를 구할 때, 행렬 곱(Matrix Multiplication) 형태로 모든 단어 쌍의 관계를 동시에 계산합니다.
즉, RNN처럼 “이전 단어의 결과를 기다리지 않아도” 됩니다.
Q = X * W_Q
K = X * W_K
V = X * W_V
Attention = softmax(QKᵀ / √d) * V이 연산은 모두 행렬 단위 계산이므로, GPU의 장점인 벡터화(vectorization) 와 병렬 행렬곱 연산을 100% 활용할 수 있습니다.
따라서 Transformer는 문장 전체를 동시에 처리할 수 있고,
RNN 대비 10~100배 이상 빠른 학습 속도를 보입니다.
✅ 특징
- 문장 내 멀리 떨어진 단어 관계도 포착 가능
- GPU 병렬 연산 가능 → 학습 속도 향상
| 비교 항목 | RNN/LSTM | Transformer |
|---|---|---|
| 처리 방식 | 순차적 (한 단어씩) | 병렬적 (전체 문장 한 번에) |
| 문맥 이해 | 인접한 단어 중심 | 모든 단어 간 관계 파악 (Attention) |
| 속도 | 느림 | 빠름 (GPU 병렬화 최적) |
| 한계 | 긴 문맥 기억 불가 | 전역 문맥 학습 가능 |
| 대표 모델 | LSTM, GRU | GPT, BERT, ViT 등 |
🌍 참고자료

도움이 되었다면, 공감/댓글을 달아주면 깃짱에게 큰 힘이 됩니다!🌟
비밀댓글과 메일을 통해 오는 개인적인 질문은 받지 않고 있습니다. 꼭 공개댓글로 남겨주세요!