
💋 코드저장소
[1단계 - 지하철 정보 관리 기능] 깃짱(조은기) 미션 제출합니다. by eunkeeee · Pull Request #35 · woowacou
안녕하세요 서브웨이! 저는 깃짱이라고 합니다. 지난번에 샘플 코드와 제 코드가 섞여서 리뷰하기 매우 어려웠을 것 같아요 죄송합니다ㅠㅠ 샘플 코드를 다 날려버리고, 다시 돌아가는 애플리
github.com
[2단계 - 경로 조회 기능] 깃짱(조은기) 미션 제출합니다! by eunkeeee · Pull Request #134 · woowacourse/jwp-s
안녕하세요 서브웨이! 이번 미션 통해서 처음부터 도메인 코드가 라이브러리와 강하게 결합하면 어떻게 되는지 잘 배운 것 같습니다.....ㅠ ㅋㅋㅋ이제 앞으로는 이렇게 만들지 않겠습니다!!!!!
github.com
💋 감정회고
이번 미션은 진짜 우당탕탕이었다.. 따라서 감정 회고부터..
이전 기수 개발자들이 최대한 우테코에서 시행착오를 많이 거치라는데, 이렇게까지 거칠 필요가 있었을까..?
지금 생각해보면 말도 안되는 일을 많이 했고, 나름 빨리 깨달을 정도로 엄청 말도 안되는 일도 많이 했닼ㅋㅋ
무튼 그래서 수습하느라 많은 것들을 왜 하지 않는게 좋다고 하는지, 그저 안될 것 같다는 느낌이 있긴 했지만...
예를 들어서, 도메인을 빈으로 등록하면 편할 것 같다는 생각이 들어서 하려고 했고, 옆에서 오잉이 그거 하면 안되지 않아?라고 이야기하기는 했지만, 오잉도 했을 때의 단점은 겪어본 적 없기 때문에 제대로 단점에 대해 설명해주지는 못했고, 그래서 나는 오잉에게 '느낌 지향 프로그래밍'이라며, 느낌 지향을 피하기 위해서 직접 해봤다. ㅋㅌㅌㅌㅋㅋㅋ근데 느낌적으로 (안)해보는 것도 괜찮은 것 같기도 하다.
무튼 이번 미션 진행하면서 유독 힘듦을 많이 느꼈다.
나름 내 자바인생 9개월차...? 스프링 1개월차 만에 첫 좌절 경험이라고 봐도 될 것 같다.
나는 스트레스 받으면 여기저기 돌아다니면서 노는 편인데...
중간에 1단계 제출 끝나고는 북악 스카이웨이,
그리고 주말을 틈타 중랑천 장미축제, 아카라카(학교 축제), 노들섬 등등 유난히 더 열심히 놀러다닌 것 같기도 하다.
미션보다 논게 세어보니 더 대단한 것 같네... 머쓱
💋 어려웠던 점
이번 미션 유독 어려웠던 건, 나와 페어 모두 스프링을 처음 공부했다는 것이다.
나는 비전공자인데다, 레이어드 아키텍처를 아직 코드로 제대로 써보지도 못하고, 이론으로만 어렴풋이 알고 있었다.
✔ 조회 데이터는 DB에서 꺼내오자!
게다가 복잡한 도메인을 스프링 MVC에 연결하기는 너무 어려웠던 데다가, DB에 대한 숙련도도 낮아서 전반적으로 애플리케이션에 대한 상상력이 현저히 떨어졌다. 정보를 조회하기 위해 가져오는 작업을 DB로부터 가져와야 할지, 도메인으로부터 가져와야 할 지도 '고민'을 하고, 도메인으로부터 가져오겠다는 잘못된 생각을 하고, 그것을 달성하기 위해서 스프링 빈이 싱글톤으로 관리된다는 것을 역으로 이용하는 신기한 코드를 작성하기도 했다.

위 코드는 뭐가 이상할까?
Subway라는 도메인의 가장 큰 부분을 빈으로 등록해서 가져오고 있다. 싱글톤으로 관리되기 때문에, 현재 미션에서 만약에 세상에 지하철 노선도가 딱!!! 하나라면 모르겠지만, 이미 상태를 가지는 필드도 가지고 있기 때문에 만약에 A나라와 B나라가 같은 애플리케이션으로 각기 다른 지하철 노선을 관리하고 싶다면, 불가능할 것이다. ㅎㅎㅎㅎㅎㅎ
어떻게 해결할 수 있을까?
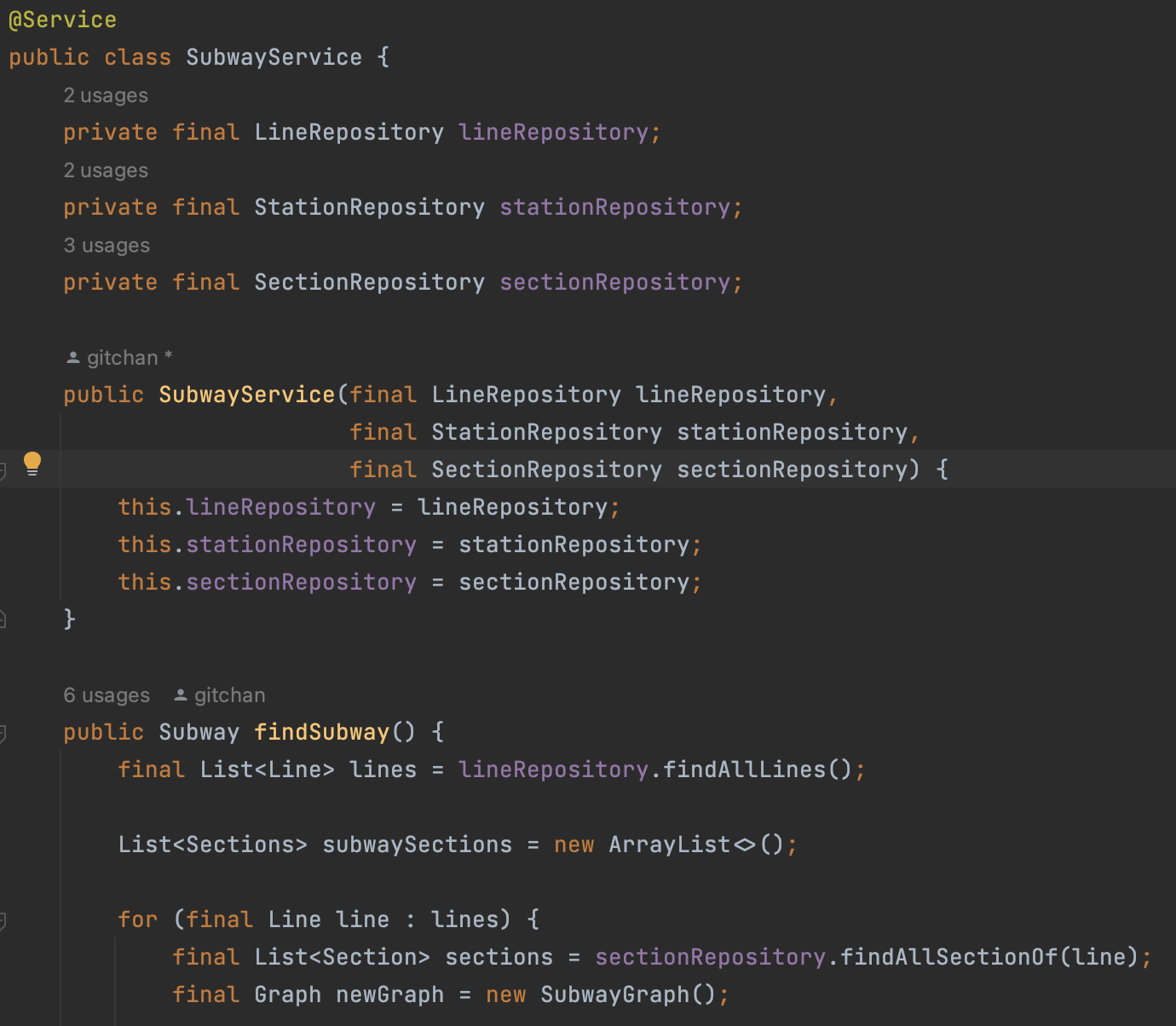
이렇게 다른 레포지토리로부터 데이터를 찾아와서, 내가 원하는 도메인의 형태로 조립해야 한다!
ㅎㅎㅎㅎ 알고나니 당연한데 머쓱
✔ 도메인과 엔티티 객체는 어떤 점이 어떻게 다를까?
아무래도 여러 가지로 아직 역량이 모라자다 보니깐, DB에 저장이라는 기능을 '구현'하는 것에 급급해서 많은 부분들을 놓쳤다.
레벨1 내내 공부했던 객체지향적인 설계와 도메인간의 관계에 대해서 조금 더 고민해보고 작성을 했어야 했다.
비록 DB에는 저장되지 않는 정보일지라도, URL을 통해서 계층적인 관계가 드러난다면, 도메인에서는 그 계층을 조금 더 적극적으로 반영해야 했다!


✔ 도메인에서 돌아다니는 객체에 식별자(id)가 필요하다면 먼저 저장한다.
id를 식별자로 저장되는 애플리케이션이기 때문에 어느 시점에 DB에 저장하는 지도 모두 다 Service 내에서 얽혀 있었기 때문에 DB 부분이 더 어려웠다. 처음에는 아예 이해가 안되고 모호하게 느껴졌지만, 지금은 조금은 이해한 상태이다.
id를 필드 값으로 가지는 객체는 아이디가 '식별자'의 역할을 제대로 할 수 있도록, 아이디를 기준으로 같은 객체인지 비교한다.
도메인 로직 과정에서 같은 객체인지 알 필요가 있다면, 아이디를 기준으로 알아야 하는데, 만약 도메인 객체에 id가 null이라면 DB에 저장하기 이전의 상태이므로 먼저 저장한 후 도메인 로직을 진행한다.


✔ 라이브러리를 사용하는 코드는 도메인과 최대한 엮이지 않도록 주의한다.

또 2단계에서 최단 경로를 구해야 하기 때문에, 다익스트라 알고리즘을 위한 라이브러리를 사용하기 위한 Graph 라이브러리를 처음 도메인 코드부터 사용하기 시작했는데, 도메인이 '특정' 라이브러리에 강하게 결합되면 어떻게 되는지도 아주 열심히 배웠다. 강하게 결합될 수록 사소한 부분에서도 라이브러리의 코드에 영향을 받았고, 라이브러리의 변동 가능성은 둘째 치더라도, 내가 라이브러리의 기능을 정말 완벽하게 알지 않는다면... 라이브러리의 직관적이지 않은 메서드 시그니처나 설정 방법에서 나도 모르게 라이브러리 내의 기본값이 내가 의도하는 것과 달리 계속 입력된다는 것을 영원히 알 수 없다. 이건 컴파일 에러도 나지 않고, 절대 찾을 수가 없다.
도메인은 역시 내가 믿을 수 있는 나의 코드로 최대한 라이브러리를 제외한 채로 작성하고, 이후에 내가 필요한 기능이 생기면 그때 다른 패키지 (이를테면 허브로 따지면 infrastructure던가..?) 에서 내가 필요한 기능의 라이브러리를 최소한으로 활용하는 것이 유익하다는 것을 알게 되었다.
💋 새로 배운 점
✔ http-request.http
이건 허브한테 배워서 사용해 봤는데, 리뷰어 반응이 엄청나게 좋았다.

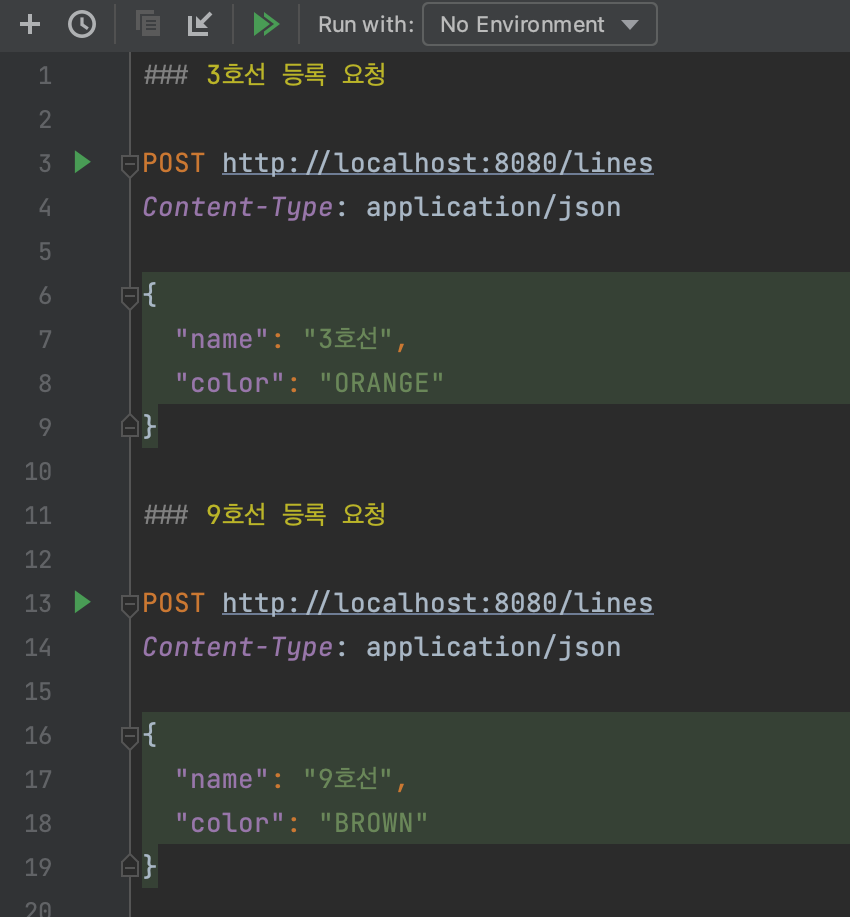
이런식으로 하면 PostMan을 통해서 요청을 보낸 것과 동일한 효과가 있는데, 인수테스트와 비슷하게 쭈루룩 테스트하기 아주 편리했다.
✔ ATDD (인수테스트)
말랑이한테 인수테스트에 대해서 배웠다. 바로 내 코드에 적용해봤다!
인수테스트는 Acceptance라는 이름인데, 여기서 한국어로 '인수'는 '수용'을 뜻하는데, 소프트웨어 개발이 끝나고 사용자가 수용할 수 있는 상태가 되었을 때 테스트가 이루어지기 때문에 이런 이름이다.
아래는 내가 작성한 인수 테스트 일부이다. 이렇게 사용자가 실제로 사용할 법한 시나리오를 생각해서 인수 테스트를 작성하면 된다.
@Test
void 전체_노선을_조회한다() {
final long 노선_9호선_아이디 = 노선_생성하고_아이디_반환(노선_9호선);
final long 고속터미널_아이디 = 역_생성하고_아이디_반환(역_고속터미널);
final long 사평역_아이디 = 역_생성하고_아이디_반환(역_사평역);
노선에_최초의_역_2개_추가_요청(
new InitialSectionCreateRequest(
노선_9호선_아이디,
고속터미널_아이디,
사평역_아이디,
5
));
존재하는_노선에_역_1개_추가_요청(
노선_9호선_아이디,
new SectionCreateRequest(
고속터미널_아이디,
사평역_아이디,
3
));
final ExtractableResponse<Response> response = 전체_노선_조회_요청();
assertAll(
() -> assertThat(response.statusCode()).isEqualTo(OK.value()),
() -> assertThat(response.body()).isNotNull()
);
}
강의에서 들은 내용 중 인상적이었던 것은, 인수테스트를 작성하면 생산성이 높아진다는 것과, 구현의 끝이 어디인지 확실히 할 수 있다는 것이었다. 그래서 개발자는 다음 일이 무엇인지 생각하지 않기 때문에 헤매는 일이 적고, 더 편안하게 퇴근하고 잠을 잘 수 있다. (갑자기 버그가 떠오른다거나 그렇지 않을 테니깐)
✔ 커스텀 예외를 활용한 400, 500대 에러 구분

처음에 이걸 보고는 IllegalArgumentException은 클라이언트가 잘못한 것 아닌가? 싶었는데, 노놉!
내가 습관적으로 그냥 IAE를 사용하고 있었던 것 뿐이지, 이건 표준 예외이기 때문에 나 말고 다른 사람들, 외부 라이브러리 모두 다 쓴다. 따라서 서버 잘못으로도 IAE가 뜰 수 있는 것!
이번에 해결한 방법은 SubwayException이라는 커스텀 예외를 만들고, 다른 구체적인 InvalidSubwayException, InvalidStationException 등에 대해서는 SubwayException을 상속하는 방식을 사용했다.
그리고 아래의 코드에서처럼, SubwayException과 상속한 클래스에 대해서는 정확하게 400대,
그외 IAE에 대해서는 500대의 상태 코드를 보내주도록 수정했다.
@RestControllerAdvice
public class GlobalExceptionHandler {
private static final Logger logger = LoggerFactory.getLogger(GlobalExceptionHandler.class);
@ExceptionHandler(Exception.class)
public ResponseEntity<ExceptionResponse> handleException(Exception exception) {
logger.error(exception.getMessage(), exception);
return ResponseEntity
.internalServerError()
.body(new ExceptionResponse("알 수 없는 오류가 발생했습니다. 잠시 후에 다시 시도해주세요."));
}
@ExceptionHandler(IllegalArgumentException.class)
public ResponseEntity<ExceptionResponse> handleIllegalArgumentException(final IllegalArgumentException exception) {
logger.warn(exception.getMessage(), exception);
return ResponseEntity
.badRequest()
.body(new ExceptionResponse("잘못된 인자가 전달되었습니다."));
}
@ExceptionHandler(SubwayException.class)
public ResponseEntity<ExceptionResponse> handleSubwayException(final SubwayException exception) {
logger.warn(exception.getMessage(), exception);
return ResponseEntity.badRequest()
.body(new ExceptionResponse(exception.getMessage()));
}
}
✔ Repository 계층과 DAO의 차이
주노의 코드를 보니, DAO와 Repository 계층을 나누어 놨는데, (리팩터링 이전이라) 뚜렷하게 다르게 사용한 의도가 보이지 않아서, 질문했다.
주노가 아주아주 친절하게 답변해줬다.

나의 언어로 정리하자면,
Service에서는 도메인의 비즈니스 로직만 수행하고, 어떤 테이블과 어떤 테이블이 연관되어 누구를 저장한다와 같은 약간 DB와 관련된 구질구질한 일들은 Repository 계층이 하도록 한다!
결과적으로, 서비스는 디비에서 무슨 일이 일어나는지 관계없이 레포지토리에 호출만 하고, 각각의 테이블을 관리하는 dao는 각 테이블과 1대1 로 동일하게 생긴 entity로 저장되는데, 이 모든 복잡한 저장과 관련된 프로세스는 레포지토리에서 한다!
@Repository
public class DbSectionRepository implements SectionRepository {
private final StationDao stationDao;
private final SectionDao sectionDao;
// 이처럼 하나의 레포지토리에서도 여러 가지 테이블에 접근할 필요가 있다.
public DbSectionRepository(final StationDao stationDao, final SectionDao sectionDao) {
this.stationDao = stationDao;
this.sectionDao = sectionDao;
}
@Override
public Section save(final Long lineId, final Section section) {
// ...
final Long id = sectionDao.insert(sectionEntity).getId();
return new Section(id, section.getUpStation(), section.getDownStation(), section.getDistance());
}
@Override
public void delete(final Long lineId, final Section section) {
sectionDao.delete(lineId, section.getUpStation().getId(), section.getDownStation().getId());
}
@Override
public void deleteSection(final Long lineId, final Long upStationId, final Long downStationId) {
sectionDao.delete(lineId, upStationId, downStationId);
}
@Override
public List<Section> findAllSectionOf(final Line line) {
// stationDao, sectionDao를 모두 사용하는 메서드
final List<SectionEntity> sectionEntities = sectionDao.findBy(line.getId());
return sectionEntities.stream()
.map(sectionEntity -> new Section(
Station.from(stationDao.findBy(sectionEntity.getUpStationId()).get()),
Station.from(stationDao.findBy(sectionEntity.getDownStationId()).get()),
sectionEntity.getDistance()))
.collect(Collectors.toList());
}
// ...
}
✔ 테스트 공통 설정을 상속 구조로 만들면 테스트가 빨라진다!
리뷰어가 테스트 공통 설정의 상속과 관련된 좋은 글을 공유해 줬다.
내 코드에 곧바로 적용해 봤는데,
아래와 같이 내 테스트에 필요한 설정들, 여기서는 어노테이션과 BeforeEach, AfterEach 등으로 표현되어 있는데, 전체 테스트에 필요한 내용들을 먼저 적어놓고, 이 클래스를 상속해서 다른 구체적인 테스트 클래스를 만들었다.
@SuppressWarnings("NonAsciiCharacters")
@DisplayNameGeneration(DisplayNameGenerator.ReplaceUnderscores.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class IntegrationTest {
@LocalServerPort
int port;
@Autowired
private JdbcTemplate jdbcTemplate;
@BeforeEach
public void setUp() {
RestAssured.port = port;
}
@AfterEach
void tearDown() {
jdbcTemplate.update("DELETE FROM station");
jdbcTemplate.update("DELETE FROM line");
jdbcTemplate.update("DELETE FROM section");
}
}
class LineIntegrationTest extends IntegrationTest {
// ...
}
💋 내가 궁금했던 것
✔ Created에 대해서 Location, 생성된 리소스 중 어떤 것을 반환해야 할까? 둘 다 반환할까?
앞으로는 리소스의 Location만 반환할 예정!

'우아한테크코스5기' 카테고리의 다른 글
| [우테코] 장바구니 협업 미션 회고: 협업을 잘 하기 위한 노력 (1) | 2023.06.07 |
|---|---|
| [우테코] 레벨로그: 레벨2 동안 공부한 내용들을 정리하며 (3) | 2023.06.07 |
| [우테코] 장바구니 미션 1단계 회고(feat. 현구막): 우당탕탕 스프링 공부하기! 자세한 내용은 목차 참고 (4) | 2023.05.04 |
| [우테코] 레벨2에서 학습할 키워드 (1) | 2023.04.21 |
| [우테코] 인프런 CTO 이동욱님의 '자존감 기둥 세우기' 강연을 듣고 (3) | 2023.04.19 |